Kimi K2 & the Dawn of Open-Source Agents

Why Moonshot AI’s new model is more than “just another drop”
TL;DR
- Kimi K2 is the first open-weight model that rivals Anthropic’s Claude series on tool-calling accuracy—the key ingredient for reliable AI agents.
- At 1 trillion parameters (Mixture-of-Experts, ~32 B active per token) it’s huge, but still cheap enough to run behind an API or in a quantised local setup.
- Expect a flood of distilled, smaller models trained on K2-generated traces—just as DeepSeek R1 kick-started the “reasoning era” a year ago.
- Licence quirks and slow raw throughput are real drawbacks, but neither blocks its impact.
We’re All Tired of Model Hype—So What’s Different Here?
New LLM announcements hit Twitter/X daily. Most fade in a week.
Kimi K2 matters because it nails the last proprietary moat: reliable function/tool calls.
Until now, if you cared about end-to-end agent success rates (think five API calls per user prompt), you paid Claude-prices or you lived with 80-ish % reliability. K2 jumps that number into the 90s—in an open model.
Quick Specs at a Glance
| Feature | Kimi K2 |
|---|---|
| Architecture | 1 T-param Mixture-of-Experts (32 B active) |
| Context Window | 1 M tokens |
| Training Corpus | 15 T tokens (web, code, academic) |
| Optimizer | Muon |
| Licence | Modified MIT (disclosure if > $20 M rev or 100 M MAU) |
| Weight Size | 960 GB (yes, really) |
Why Tool-Call Accuracy Is a Big Deal
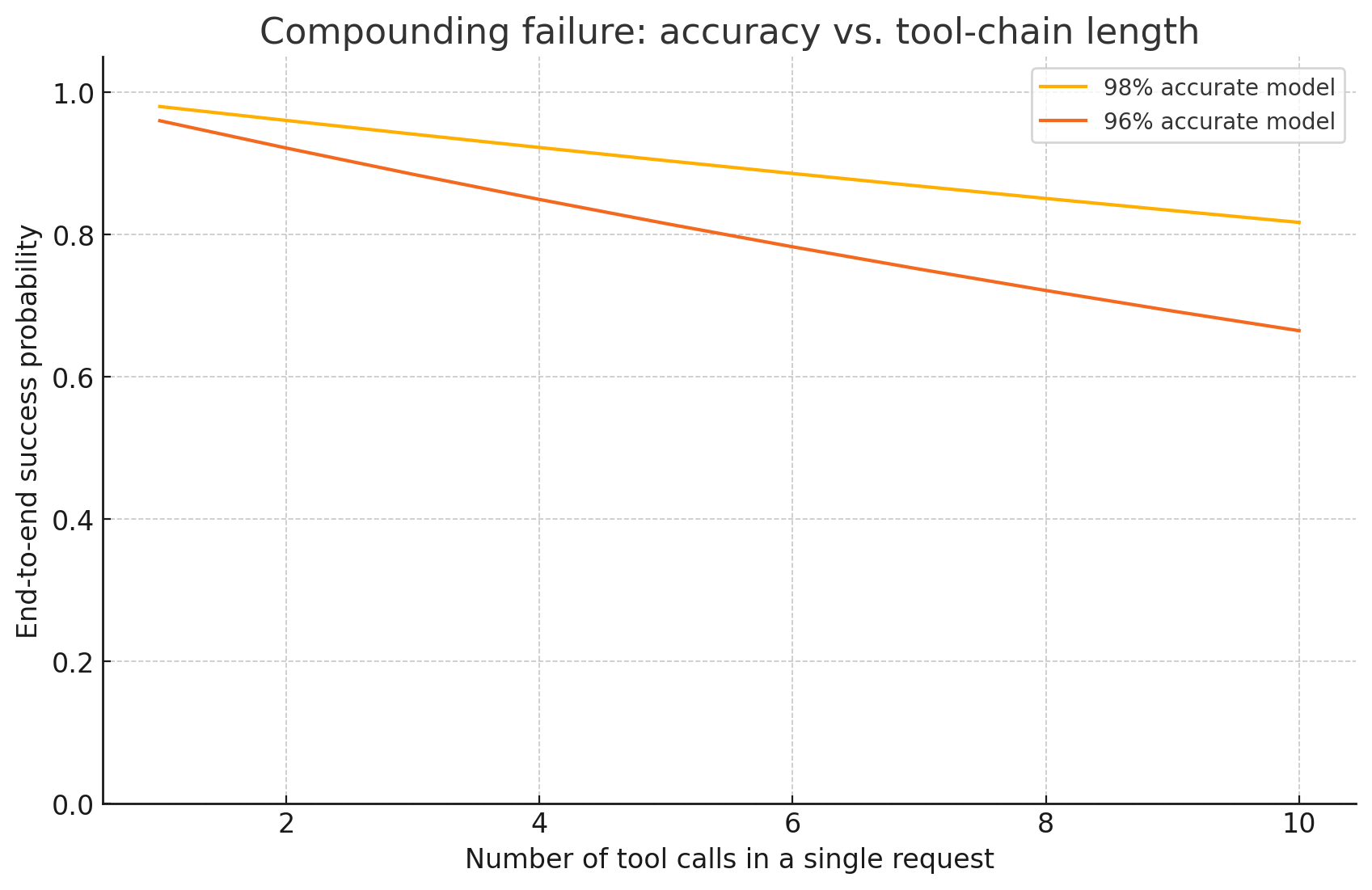
Imagine your chatbot needs five tool calls to answer a question:
Model accuracy 98 % ⇒ (0.98)^5 ≈ 90 % success
Model accuracy 96 % ⇒ (0.96)^5 ≈ 80 % successA two-point drop doubles failure rates. That’s why Anthropic could charge premium rates for Claude 3.5+: nothing else was as consistent.
Kimi K2 finally changes those economics.
A Short History of “Thinking vs. Doing”
| Year | Breakthrough | Result |
|---|---|---|
| 2023 | OpenAI “01”: hidden chain-of-thought | Reasoning becomes table-stakes |
| 2024 | DeepSeek R1 open-weights + exposed reasoning | Community training boom |
| 2025 | Kimi K2 open-weights + near-Claude tool calls | Agentic era begins |
DeepSeek R1 proved that exposing internal reasoning lets the community generate endless high-quality synthetic data. K2 offers that same fountain—this time for acting, not just thinking.
Under the Hood (MoE in a Nutshell)
- 256 experts, top-2 gating → only ~13 B parameters fire per token.
- You get near-GPT-4 quality with mid-tier GPU bills, at the cost of latency.
- The 1 M-token window means K2 can plan across huge instruction chains or digest entire codebases in a single pass.
The Licence Curveball
Modified MIT sounds nice, but one clause bites:
Products with > $20 M monthly revenue or > 100 M MAU must display
“Powered by Kimi K2” in-app.
For hobby projects and most SaaS this is a non-issue.
For Big Co distillations or stealth infra plays it’s… murky. Enforcement? Unknown. Expect lawyers to test the edges.
Limitations (Know Before You Build)
- Speed – public hosts report 15-30 tokens/s. Fine for batch jobs, painful for chat UIs.
- Storage/VRAM – 960 GB raw weights; even 4-bit quant requires serious GPU RAM.
- No built-in reasoning or multimodal (yet).
- Chinese endpoints – consider data-residency rules if you hit Moonshot’s API.
The Distillation Playbook (What Happens Next)
- Use K2 to auto-generate millions of perfectly-shaped tool-call transcripts in your domain.
- Fine-tune a 7-13 B Llama-3, Quen, or Mistral on that data.
- Deploy an agent that runs at 200 tokens/s on commodity GPUs—yet inherits ~95 % of K2’s reliability.
- Open-source it → the floor rises for everyone.
Exactly what DeepSeek did with R1 ⇒ Llama/Quen distills—expect the same curve for tool-calling.
Real-World Things You Can Build Today
- DocOps bots that pull internal APIs, write markdown, and open PRs.
- E-commerce agents doing price look-ups, inventory checks, and order creation.
- Code-refactor assistants: git diff, run tests, push fixes—all hands-free.
- Minecraft research (MCBench) proving 3-D tool control from text alone.
Getting Started Quickly
- Spin up an endpoint – Moonshot Cloud or an OpenRouter host.
- Define 3-5 JSON-schema tools you wish the model to call.
- Prompt-test; collect successful traces.
- Fine-tune a smaller model or just ship K2 behind a queue for now.
- Measure end-to-end task success vs. Claude—tweak, repeat.
Looking Further Ahead
- OpenAI’s delayed open-weight model will likely join K2 & DeepSeek as the “tri-force” of free data fountains.
- Community LoRA hubs will swap in domain-specific tool vocabularies overnight.
- Edge MoE: phones run expert shards, cloud runs router → latency plummets.
- Multimodal K2 could land before 2026, folding vision/audio into the same agent loop.
Final Thoughts
Kimi K2 is not the model you’ll chat with every day—yet.
But history says we’ll look back on July 2025 as the moment agent reliability went open-source, much like December 2024 marked reasoning’s liberation.
If you care about autonomous workflows, start harvesting tool-call traces now.
The next wave of compact, lightning-fast, actually dependable agents will be trained on the data you generate this summer.
Happy building!